pod 相关知识点-1
简介
- pod 是容器服务的最小单位
- pod 可以由1个或者多个容器组合而成,同属于一个Pod的多个容器应用之间访问时仅需要通过localhost 就可以通信。
静态pod
静态pod 是由 kubelet 进行管理的仅存在一特定的Node上的Podcast。不能通过API Server进行管理。无法与ReplicationController、Deployment或者DaemonSet进行关联,并且kubelet无法对它们进行健康检查
创建静态Pod 有两种方式:配置文件方式和HTTP方式。
- 配置文件方式
首先,需要设置kubelet的启动参数 "--pod-manifest-path"(或者在kubelet配置文件中设置staticPodPath,这也是新版本推荐的设置方式)"--pod-manifest-path"将逐渐被弃用,指定 Kubelet需要监控的配置文件所有的目录,kubelet会定期扫描该目录,并根据该目录下的.yaml 或者.json 文件进行创建操作。(默认都是开启的)

- HTTP 方式
通过设置kubelet的启动参数 "--manifesturl",kubelet将会定期从该URL 地址下载Pod的定义文件,并以.yalm 或 .json 文件的格式进行解析
提示
由于静态Pod无法通过API Server 直接管理,所以在Master上尝试删除这个Pod时,会使其变成Pending状态,且不会被删除。删除Pod操作,只能到其所有的Node上将其定义文件从目录下删除即可。
Pod容器共享Volume
同一个Pod中的多个容器能够共享Pod级别的存储卷Volume。Volume可以被定义为各种类型。
pod-volume的yaml配置
ConfigMap概述
ConfigMap供容器使用的典型用法如下:
- 生成为容器内的环境变量
- 设置容器启动命令参数(需要设置环境变量)
- 以Volume的形式挂载为容器内部的文件或目录
ConfigMap以一个或多个key:value的形式保存在Kubernetes系统中供应用使用,即可以用于表示一个变量的值(如hostname=server),也可以用于表示 一个完整配置文件的内容(如:server.xml=<?xml....>)
可以通过YAML 配置文件或者直接使用kubectl create configmap 命令行的方式来创建ConfigMap。
创建ConfigMap资源对象
通过YAML 配置文件方式创建
通过kubectl 命令行创建
不使用YAML 文件,直接通过kubectl create configmap 也可以创建ConfigMap ,可以使用参数 --from-file 或 --from-literal 指定内容,并且可以在一行命令中指定多个参数
#通过--from-file 从文件创建
kubectl create configmap NAME --from-file=[key=]source --from-file=[key=]source
#通过--from-file 从目录创建
kubectl create configmap NAME --from-file=config-file-dir
#通过--from-literal 从文件创建,直接将指定的key#=value# 创建为ConfigMap 的内容
kubectl create configmap NAME --from-literal=key1=value1 --from-literal=key2=value2例如:
#使用--cofnig-fil创建,configmap 的名字是cm-name key是文件名server.xml value值是 server.xml 内容
kubectl create configmap cm-name --from-file=server.xml
#使用--cofnig-fil创建,假设在configfiles目录下包含两个配置文件,文件名则为key ,内容为 value
kubelet create configmap cm-name --from-file=configfiles
#使用 --from-literal 参数进行创建,两个key,key1:loglevel,key2:appdatadir ,value1:info,value2:/var/data
kubectl create configmap cm-name --from-literal=loglevel=info --from-literal=appdatadir=/var/data容器应用对ConfigMap 的使用,有以下两种方法
- 通过环境变量获取ConfigMap 中的内容
- 通过Valuer挂载的方式将ConfigMap 中的内容挂载为容器内部的文件或目录
在Pod中使用ConfigMap
1. 通过环境变量使用ConfigMap
spec:
containers:
env:
- name: APPLOGLEVEL
valueFrom:
configMapKeyRef:
name: cm-appvars #ConfigMap的名字
key: apploglevel #configMap中key
- name:
valueFrom:
configMapKeyRef:
name: cm-appvars
key: appdatadirKubernetes从1.6 版本引用envFrom 实现Pod环境中将ConfigMap(也可以是secret资源对象)中所定义的key=value 自动生成环境变量
spec:
containers:
envFrom:
- configMapRef;
name: cm-appvars #根据cm-appvars中的key=value自动生成环境变量
#变量名的大小写和key一致需要说明的是,环境变量受POSIX命名规范的约束,不能以数字开关,如果包含非法字符 ,系统将跳过该条环境变更的创建,并记录一个Event来提示环境变量无法生成,但并不阻止Pod启动
2. 通过volumeMount使用ConfigMap
spec:
containers:
volumeMounts:
- name: squid #挂载点的名字
mountPath: /var/squid #挂载的路径
volumes:
- name: squid #指定挂载点的名字
configMap:
name: squid #指定ConfigMap的名字
items:
- key: squid #指定ConfigMap的key
path: squid.conf #指定挂载成文件的名字如果在引用ConfigMap 的时候不指定items,则使用volumeMount方式在容器的内的目录下为每个item 都生成一个文件名为key的文件
3. 使用ConfigMap的限制条件
- ConfigMap必须在Pod之前创建
- ConfigMap受Namespace限制 ,只有处于相同的Namespace中的Pod才可以引用它
- ConfigMap中的配额管理还未实现。
- kubelet只支持可以被API Server 管理的pod 使用ConfigMap,静态Pod无法使用ConfigMap.
- 在Pod对ConfigMap进行挂载(volumeMounts)操作时,在容器内部只能技巧为目录无法挂成文件,在挂载到容器内部后,在目录将创建挂载时指定的每一个items,如果 目录已经存在,目录会ConfigMap被覆盖。如果需要保留源来的,则需要挂载到临时目录,然后复制或者连接到实际目录中去。
在容器内获取Pod信息(Downward API)
Downward API可以通过以下两种方式将Pod的信息注入到容器内部。
- **环境变量:**用于单个变量,可以将Pod 信息和Container信息注入容器内部。
spec:
containers:
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.namevalueFrom 这种特殊的语法是Downward API的写法,目前Downward API 提供了以下变量:
- metadata.name
- status.podIP:Pod 的IP地址,属于状态数据,而非元数据
- metadata.namespace
spec:
containers:
env:
- name: MY_CPU_REQUEST
valueFrom:
resourceFieldRef:
containerName: test-container
resource: requests.cpu注意valueFrom这种特殊的Downward API语法,目前resourceFieldRef 可以将容器的资源请求和资源限制等配置设置为容器内部的环境变量。
requests.cpu
resuests.memory
limits.cpu
limits.memory
Volume挂载: 将数组类信息生成文件并挂载到容器内部。
spec:
containers:
volumeMounts:
- name: podinfo
mountPath: /etc/podinfo
volumes:
- name: podinfo
downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "annotations"
fieldRef:
fieldPath: metadata.annotations这里要注意“volumes” 字段中downward API 的特殊语法,通过items的设置,系统会根据path的名称生成文件。根据上例,系统将在容器内生成/etc/labels和/etc/annotations 两个文件。文件包含的将会是metadata中labels和annotations中的数据。
Pod生命周期和重启策略
Pod 状态:
| 状态值 | 描述 |
|---|---|
| Pending | API Server 已经创建,但是Pod内还有一个或者多个容器的镜像没有创建,包括正在下载镜像的过程 |
| Running | Pod内所有容器均已创建,且至少有一个容器处理运行状态,正在启动状态或者正在重启状态 |
| Succeeded | Pod 内所有容器均成功执行后退出 ,且不会再重启 |
| Failed | Pod 内所有容器均以退出 ,但至少有一个容器退出为失败状态 |
| Unknown | 由于某种原因无法获取该Pod的状态,可能是由于网络通信不畅导致。 |
Pod 的重启策略(restartPolicy) 应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。
Pod的重启策略包括 Always 、OnFailure和Never,默认值为 Always
- Always: 当容器失效时,由kubelet自动重启该容器
- OnFilure: 当容器终止运行且退出码不为0时,由Kubelet自动重启该容器
- Never: 不论容器运行状态如何,kubelet都不会重启该容器
kubelet重启失效容器的时间间隔以sync-frequency乘以2n 来计算,例如 1、2、4、8倍等,最长延时5min,并且在成功重启后的10min后重置该时间。
每种控制器对Pod的重启策略要求如下:
- RC 和Daemonset :必须设置为Always
- Job: OnFailure 或 Never
- kubelet:(静态Pod),在Pod 失效时自动重启它,不论将restartPolicy 设置为什么值,都不进行健康检查
Pod 健康检查和服务可用性检查
Kubernetes 对Pod的健康检查可以通过两类探针来检查 LivenessProbe 和 ReadinessProbe, kubelet定期执行这两类探针来诊断容器的健康状况。
- LivenessProbe 探针,用于判断容器是否存活(Running状态),如果不健康则杀掉,根据重启策略进行相应处理,如果容器不包含LivenessProbe 探针,则kubelet认为该容器的LivenessProbe探针返回值永远是Success.
- ReadinessProbe探针:用于判断容器服务是否可用(Ready状态),达到Ready 状态的Pod 才可以接收请求。对于Service 也将基于Pod是否Ready进行设置,如果运行过程中Ready状态变为False,则系统自动将其从Service的后端Endpoint列表中隔离出去,后续再把恢复到Ready状态的Pod加回后端列表
LivenessProbe 和 ReadinessProbe 均可通过配置以下三种方式实现。
ExecAction: 在容器内部执行一个命令,如果该命令返回码为0,则表明容器健康
TCPSocketAction: 通过容器的IP地址和端口号执行TCP检查 ,如果能够建立TCP连接,表明健康
HTTPGetAction: 通过容器的IP地址、端口及路径调用HTTP Get 方法,如果响应的代码大于等于200且小于400,则认为容器健康。
ps: 对于每种探测方式,都需要设置 initialDelaySeconds 和 timeoutSeconds 两个参数
initialDelaySeconds: 启动容器后进行首次健康检查的等待时间,单位为stimeoutSeconds: 健康检查发送请求后,等待响应的超时时间,单位为s
Kubernetes 的ReadinessProbe可以无法满足某些复杂应用对容器内服务可用状态的判断 ,所以Kubernetes 在1.11版本中引入 Pod Ready++ 特性对ReadinessProbe探测机制进行扩展,在1.14版本达到GA 稳定版,称其为Pod Readiness Gates。
通过 Pod Readiness Gates 机制,用户可以将自定义的ReadinessProbe探测方式设置在Pod 上,辅助Kubernetes 设置Pod 何时达到服务可用状态(Ready),为了使自定义的ReadinessProbe 生效,用户需要提供一个外部的控制器(Controller)来设置相应的Condition状态。
玩转Pod 调度
在Kubernetes 平台上,大多数情况下,我们会通过RC、RS、Deployment、DeamonSet、Job等控制器完成对一组Pod的创建,调度及全生命周期的自动控制任务。
- 不同的Pod之间的亲和性(Affinity)。控制Pod是否调度到相同的Node节点
- 有状态集群的调度。这些节点的启动停止次序通常有非常严格的顺序。如ZooKeeper、Elastisearch等。由于集群需要持久化保存状态数据,所以Pod需要绑定具体的PV。Kubernetes提供了StatefulSet这种特殊的副本控制器来解决问题。
- 在每个Pod上调度并且仅仅创建一个Pod副本。这种调度通常用于系统监控相关的Pod,比如主机上的日志采集、性能采集等进程需要被部署到集群中的每个节点并且只能部署一个副本,这就是DaemonSet这种特殊的Pod副本控制器所以解决的问题。
- 对于批量处理作业,需要创建多个Pod副本来协同工作,当这些Pod副本都完成自己的任务时,整个批处理作业就结束了。Job就可以解决这个问题,同时延伸出CronJob 定时作业高度控制器。
Kubernetes 1.9 版本以后,Pod副本会随着控制器的删除而删除,如果不希望这个做,则可以通过
kubectl delete replicaset my-repset --cascade=false
# replicaset 控制器类型, my-repset :自己创建的replicaset来取消这一默认特性。
Deployment 或 RC : 全自动调度
Deployment 或 RC 的主要功能之一就是自动部署一个容器应用的多份副本,以及持续监控副本的数量。在集群内始终维持用户指定的副本数量。
使用这个配置文件创建一个ReplicaSet,这个ReplicaSet会创建3个Nginx应用的Pod .
除了使用系统自动调度算法完成一组Pod的部署,Kubernetes 也提供了多种丰富的调度策略,用户只需要在Pod的定义中使用NodeSelector、NodeAffinity、PodAffinity、Pod驱逐等更加细粒度策略设置,就能完成对Pod的精准调度。
NodeSelector: 定向调度
1、首先通过kubectl label 命令能目标Node打上一些标签
#kubectl label nodes <node-name> <label-key>=<label-value>
kubectl label nodes master zone=hangzhou2、在Pod定义中加上NodeSelector 的设置。

如果我们指定了Pod的nodeSelector条件,且在集群中不存在包含相应标签的Node,则即使在集群中还有其他可供使用的Node,这个Pod也无法被成功调度
除了用户自行给Node添加标签,Kubernetes 也会给Node预定义一些标签,包括:
- kubernetes.io/hostname
- beta.kubernetes.io/os (从1.14 更新为稳定版,到1.18版本删除)
- beta.kubernetes.io/arch (从1.14 更新为稳定版,到1.18版本删除)
- kubernetes.io/os (从1.14 开始启用)
- kubernetes.io/arch (从1.14 开始启用)
NodeSlector 通过标签的方式,简单的实现了限制Node的方法。亲和性调度机制则极大扩展了Pod的高度能力。
- 更具表达力(不仅仅是“符合全部”的简单方式)
- 可以使用软件限制,优秀采用等限制方式,代替之前的硬限制,这样调度器在无法满足优先需求的情况下会退而求其次,继续运行该Pod .
- 可以依据节点上正在运行的其他Pod 的标签来进行限制,而非节点本身的标签。这样就可以定义一种规则来描述Pod之间的亲和性和互斥关系。
亲和性调度包括节点亲和性(NodeAffinity)和Pod亲和性(PodAffinity)两个维度的设置。
NodeAffinity: Node亲和性调度
目前有两种节点亲和性表达:
RequiredDuringSchedulingIgnoredDuringExecution:必须满足指定的规则才可以调度Pod到Node上(功能与NodeSelector很象,但是使用的是不同的语法)相当于硬限制PreferredDuringSchedulingIgnoredDuringExecution:强调优先满足指定规则,调度器会尝试调度Pod到Node上,但并不强求,相当于软限制。多个优先级规则还可以设置权重(weight)值,以定义执行的先后顺序。weight字段值的 范围是 1-100
- 只运行在amd64的节点上
- 尽量运行在磁盘类型为ssd的节点上。
NodeAffinity 语法支持的操作符包括 In、NotIn、 Exists 、DoesNotExist、 Gt、 Lt。虽然没有节点排斥,但是用NotIn、DoesNotExist可以实现排斥的功能。
NodeAffinity规则设置注意事项:
- 同时定义了NodeSelector和nodeAffinity,那么必须两个条件都得到满足,Pod才能最终运行在指定的Node上。
- 如果nodeAffinity指定了多个nodeSelectorTerms,那么其中一个能匹配成功即可。
- 如果在nodeSelectorTerms 中有多个matchExpressions ,则一个节点必须满足所有的
matchExpressions才能运行该Pod。
PodAffinity : Pod亲和性调度
根据节点上运行的Pod 的标签而不是节点的标签进行判断和调度,要求对节点和Pod两个条件进行匹配。
通过Kubernetes内置节点标签中的key 来进行声明,这个key的名字为topologyKey ,表达节点所属的topology范围
- kubernetes.io/hostname
- failure-domain.beta.kubernetes.io/zone
- failure-domain.beta.kubernetes.io/region
Pod亲和和互斥条件设置也是 RequiredDuringSchedulingIgnoredDuringExecution 和PreferredDuringSchedulingIgnoreDuringExecution。Pod的亲和性被定义于PodSpec的affinity字段下的podAffinity子字段中。Pod间的互斥性则被于同一层的podAntiAffinity 子字段 中
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: failure-domain.beta.kubernetes.io/zonePod 亲和性和互斥性语法也支持 In、NotIn、 Exists 、DoesNotExist、 Gt、 Lt
原则上,topologyKey 可以使用任何合法的标签key 赋值,但是出于性能和安全方面的考虑,对topologyKey有如下限制:
- 在Pod 亲和性和RequiredDuringScheduling 的Pod 互斥性的定义中,不允许使用空的topologyKey
- 如果
Admission controller包含了LimitPodHardAntiAffinityTopology,那么针对RequiredDuringScheduling 的Pod互斥性定义就被限制为Kubernetes.io/hostname,要使用自定义的topologyKey ,就要改写或禁用该控制器。 - 在PreferredDuringScheduling 类型的Pod互斥性定义中,空的topologyKey 会被解释为
kubernetes.io/hostname、failure-doamin.beta.kubernetes.io/zone及failure-doamin.beta.kubernetes.io/region的组合。 - 如果不是上述情况就可以采用任意组合的topologyKey 了
PodAffinity 规则设置注意事项:
- 除了设置 LabelSelector 和topologyKey ,用户还可以指定Namespace列表来进行限制,同样,使用LabelSelector对Namespace进行选择。Namespace的定义和LabelSelector及topologyKey同级。省略Namespace 的设置,表示使用定义了affinity/anti-affinity 的pod 所在的Namespace。如果Namespace设置为空值("")则表示所有Namespace。
- 在所有关联的requiredDuringSchedulingIgnoredDuringExecution 的matchExpressions 全都满足之后 ,系统才能将Pod 调度到某个Node上。
Taints 和 Tolerations (污点和容忍)
Taints 它让Node拒绝Pod 的运行。
Taints 和toleration 配合使用,让Pod避开那些不合适的Node,在Node 上设置一个或多个Taints 之后,除非Pod明确声明能够容忍这些污点,否则无法在这些Node运行。
Toleration是Pod 的属性,让Pod 能够(注意:是能够,而非必须)运行在标注 了Taints 的Node上。
可以使用 kubectl taint 命令为Node设置Taints.
kubectl taint nodes node1 key=value:NoSchedule
#键为key,值为value ,效果为 NoSchedule声明toleration ,下面两个Toleration 都被设置为可以容忍(Toleration)具有该Taint 的Node,使得Pod 能够被高度到node1 上:
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"或
tolerations:
- key: "key"
operator: "Exists"
effect: "NoSchedule"Pod 的 Toleration 声明中的key和effect 需要与Taint 的设置保持一致,并且满足以下条件之一:
- operator 的值是Exists(无需指定value)
- operator 的值是 Equal并且value相同。
如果不指定 operator,则默认为Equal
另外,有如下两个特例:
- 空的key 配合 Exists操作符能够匹配所有的键和值
- 空的effect 匹配所有的effect
在上面的例子中,effect 的取值为NoSchedule,还可以取值为 PreferNoSchedule ,这个值的意思是优先,也可以算做NoSchedule的软限制版本(尽量避免,但是不强制),还有另一个effect “NoExecute”
系统允许在同一个Node上设置多个Taint ,也只可以在Pod上设置多个Toleration ,kubernetes 高度器处理多个Taint和Toleration的逻辑顺序为:首先列出节点中所有的Taint,然后忽略Pod的Toleration能够匹配的部分,剩下的没有忽略的Taint就是对Pod的效果了。下面是几种特殊情况。
- 如果在剩余的Taint中存在
effect=NoSchedule,则调度器不会把该Pod 调度到这一节点上。 - 如果在剩余的 Taint 中没有
NoSchedule效果,但是有PreferNoSchedule 效果,则调度会尝试不把这个Pod 指派给这个节点。 - 如果在剩余的 Taint 中有
NoExecute效果,并且这个Pod已经在该节点上运行,则会被驱逐;如果没有在该节点上运行,则也不会再被调度到该节点上。
$kubectl taint nodes node1 key1=value1:NoSchedule
$kubectl taint nodes node1 key1=value1:NoExecute
$kubectl taint nodes node1 key2=value2:NoScheduletolerations:
- key: "key1"
operator: "Equal"
value: "value"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value"
effect: "NoExecute"结果是该Pod无法被调度到 node1 上,因为第3个 Taint没有匹配的 Toleration,如果Pod已经在Node 上,那么设置第3个Taint,它还可以继续在node1 上运行,这是因为 Pod 可以容忍前两个Taint 。(只有NoExecute才驱逐)
一般来说,如果能Node加上 effect=NoExecute 的Taint ,那么在该Node上正在运行的所有无对应Toleration的Pod都会被立刻驱逐,而且有相应Toleration的Pod永远不会被驱逐。不过系统允许给具有NoExecute效果的Toleration加入一个可选的TolerationSeconds字段,这个设置表明Pod可以在Taint添加到Node之后还能在这个Node上运行多久。
tolerations:
- key: "key1"
operator: "Equal"
value: "values1"
effect: "NoSchedule"
tolerationSeconds: 36001.独占节点
#如添加Taint
kubectl taint nodes nodename dedicated=groupName:NoSchedule这样带有合适Toleration 的Pod 就会被允许使用有Taint的节点。
2.具有特殊硬件设备的节点
kubectl taint nodes nodename special=true:NoSchedule
kubectl taint nodes nodename special=true:PreferNoSchedule使用Admission Controller 来完成这一任务会更方便。
3. 定义Pod驱逐行为,以应对节点故障(为Alpha版本的功能)
NoExecute 这个Taint 效果对节点上正在运行的Pod有如下影响:
- 没有设置Toleration的Pod会被立刻驱逐
- 配置了对应Toleration的Pod ,如果没有为tolerationSeconds赋值,则会一真留在这一节点中。
- 配置了对应Toleration的Pod 且指定了tolerationSeconds值,则会在指定时间后驱逐。
- Kubernetes从1.6 后开始引入一个Alpha版本的功能,即把节点故障标记为Taint(目前只针对node unreachable 及 node not ready ,相应的NodeCondition "Ready" 的值分别为Unknown 和False) .激活TaintBasedEvicitions功能后(在--feature-gates 参数中加入TaintBasedEvications=true) NodeController 会自动为Node设置Taint而在状态为Ready 的Node 上,之前设置过的普通驱逐逻辑将会被禁用。为了保持现存的Pod的限速(rate-limiting)设置,系统将会以限速模式逐步给Node设置Taint。
Pod的Toleration可以这样定义
tolerations:
- key: "node.alpha.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 600对于Node 未就绪状态,可以把key 设置为 node.alpha.kubernetes.io/notReady.
如果没有为Pod 指定 node.alpha.kubernetes.io/notReady 的 Toleration,那么Kubernetes会自动为Pod 加入tolerationSeconds=300的node.alpha.kubernetes.io/notReady 类型的Toleration。
同样,如果Pod没有定义node.alpha.kubernetes.io/unreachable的Toleration,那么系统会自动为其加入 tolerationSeconds=300 的 node.alpha.kubernetes.io/unreachable 类型的Toleration。
默认的Toleration由Admission Controller "DefaultTolerationSeconds" 自动加入
Pod Priority Preemption: Pod 优先级调度
对于运行各种负载(如 Service 、Job) 的中等规模或者大规模的集群来说,出于各种原因,需要提高集群的资源利用率。而提高资源利用率的常规做法就是优先级方案。不同类型的负载对应不同的优先级,同时允许集群中的所有负载所需的资源总量超过集群可提供的资源 。
基于Pod 优先级抢占(Pod Priority Preemption)的调度策略。这个调度策略被称为”抢占式调度“
- Priority,优先级
- Qos ,服务质量等级
- 系统定义的其他度量指标
优先级抢占调度策略的核心行为分别是驱逐(Evication)与抢占(Preemption),这两种行为使用场景不同,效果相同。Evication是kubelet 进程的行为,即当一个Node发生资源不足(under resource pressure) 的情况时,该节点上的kubelet进程会执行驱逐动作。当同样优先级的Pod 需要被驱逐时,实际使用的资源量超过申请量最大位数的高耗能Pod 会被首先驱逐。对于QoS等级为 "Best Effort" 的Pod来说,由于没有定义资源申请(CPU/Memroy Request)。所有它们实际使用的资源可能非常大。Preemption则是Scheduler 执行的行为,当一个新的Pod 因为资源无法满足而不能被调度时,Scheduler 可能 (有权决定)选择驱逐部分优先级的Pod 实例来满足此Pod的调度目标。这就是Preemption 机制。
Pod 优先级调度策略示例:
apiVersion: scheduling.k8s.io/v1beta1
kind: PriroityClass
metadata:
name: high-priority
value: 100000
globalDefault: false
description: "This priority class should be used for XYZ service pods only"上述YAML 文件定义一个名为high-priority 的优先级类别,优先级为 100000 ,数字越大,优先级越高,超过一亿的数字被保留,用于指派给系统组件。
在任意Pod 上引用上述Pod优先级类别:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority优先级抢占的调度方式在有多个调度(Scheduler)时。可能会导致调度陷入”死循环“状态。
一旦发生资源紧张的局面,首先要考虑的是集群扩容,如果无法扩容,则再考虑有监管的优先级调度特性,如果结合基于Namespace的资源配额限制来约束任意优先级抢占行为。
DaemonSet: 在每个Node上都调度一个Pod
DaemonSet 用于管理在集群中每个Node 上仅运行一份Pod 的副本实例。
- 在每个Node 上运行一个GlusterFS存储或者Ceph 存储的Daemon进程
- 在每个Node上运行一个日志采集程序,例如Fluentd 或者Logstach
- 在每个Node上运行一个性能监控程序,采集该Node的才能性能数据。
DaemonSet的Pod 调度策略与RC类似,除了使用系统内置的算法,也可以在Pod上定义中用NodeSelector或者NodeAffinity 来指定满足条件的Node范围进行调度。
示例挂载了物理机的两个目录"/var/log","/var/libe/docker/containers"
查看创建
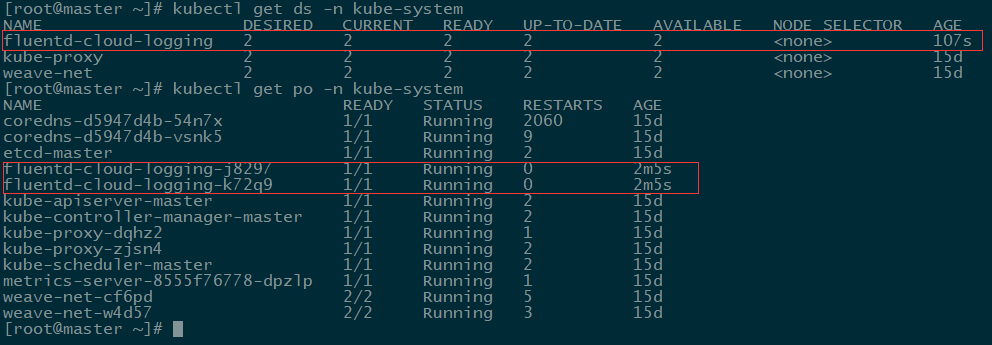
DaemonSet 在 1.6版本之后支持滚动升级,更新策略(dateStrategy) 为 RollingUpdate
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: goldpinger
spec:
updateStrategy:
type: RollingUpdateupdateStrategy 的另一个值是OnDelete,即只能手动删除了,DaemonSet创建的Pod副本时,新的Pod才会被创建出来。如果不设置updateStrategy的值,默认设置为RollingUpdate.
Job: 批处理调度
批处理任务通常并行(或者串行)启动多个计算进程去处理一批工作项(work item) 处理完成后,整个批处理任务结束。按照批处理任务实现方式不同,分为以下几种模式:
- Job Template Expansion 模式: 一个Job对象对应一个待处理的Work item ,有几个Work item ,就产生几个独立的Job ,适用场景: Work item 数量少,每个Work item 都要处理的数据量较大的场景
- Queue with Pod Per Work Item 模式: 采用一个任务队列存放Work Item ,一个Job对象作为消费者去完成这些Work Item ,这种模式Job 会启动N 个Pod,每个Pod 都对应一个Item。
- Queue with Variable Pod Count模式: 也是采用一个任务队列存放Work Item ,一个Job对象作为消费者去完成这个Work item ,但与上面的模式不同,Job 启动的Pod 数量是可变的。

- Single Job with Static Work Assignment 模式 : 一个Pod产生多个Pod ,采用程序静态方式分配任务项,而不是采用队列模式进行动态分配。
考虑到并行的问题,Kubernetes 将Job分以下三类:
- Non-parallel Jobs
通常一个Job只启动一个Pod,除非Pod异常,才会重启该Pod ,一旦Pod 正常结束,Job将结束。
- Parallel Jobs with a fixed completion count
并行Job 会启动多个Pod ,此时需要设定Job 的.spec.completions 参数为一个正数,当正常结束的Pod 数量达到些参数设定的值,Job结。此外,Job 的 .spec.parallelism 参数用来控制并行度,即同时启动几个Job来处理Work item 。
- Parallel Jobs with a work queue
任务对列方式的并行Job需要一个独立的Queue,Work item 都在一个Queue中存放,不能设置Job的.spec.completions参数。此时Job有以下特性
- 每个Pod 都能独立判断和决定是否还有任务项需要处理。
- 如果某个Pod 正常结束,则Job不会再启动新的Pod 。
- 如果一个Pod成功结束 ,则此时应该不存在其他Pod 还在工作的情况,它们应该都处于即将结束、退出的状态
- 如果所有Pod 都结束了,且至少有一个Pod 成功结束,则整个Job 成功结束。
常用场景:
Single Job with Static Work Assignment 模式 : 使用模板,制作出多个模板
Parallel Jobs with a fixed completion count:使用任务队列存放Work item ,比如RabbitMQ,客户端把任务变成Work item 放入任务队列 ,Worker 从任务队列中拉取一个Work item 并处理,处理完后即结束进程。
Parallel Jobs with a work queue:由于这种模式下,Worker程序需要知道队列中是否还有等待处理的Work item ,如果有就取出来处理,否则就认为所有工作都完成并结束程序 ,所以任务队列通常要采用Redis或者数据库来实现。
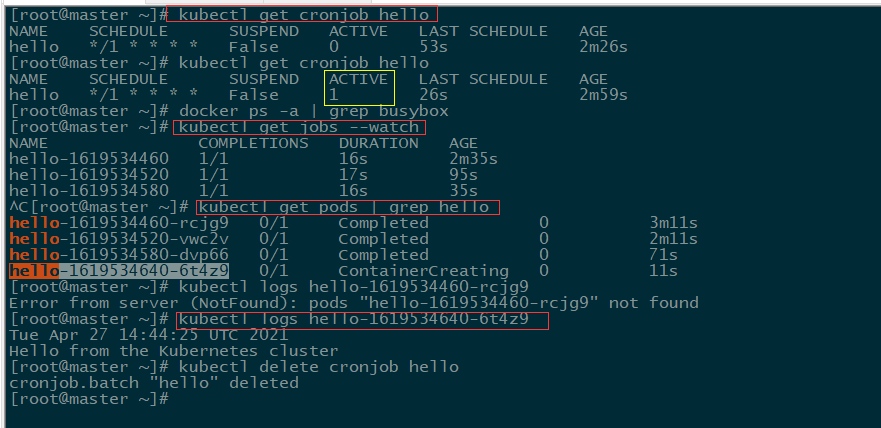
Cronjob:定时任务
定时任务类似 Linux Cron 的定时任务
Minutes Hours DayofMonth Month DayofWeek
分 时 日 月 周- Minutes:
,-*/,这4个字符,有效范围为0~59 - Hours:
,-*/,这4个字符,有效范围-~23 - DayofMonth:
,-*/?LWC,这8个字符,有效范围0~31 - Month:
,-*/,这4个字符,有效范围012的整数或JANDEC。 - DayofWeek:
,-*/?L#C,这8个字符,有效范围为17的整数或SUNSAT,1表示星期天。 *表示匹配任意值/表示从起始时间开始触发,间隔固定时间再触发。

自定义调度器
一般情况下,每个新的Pod都会由默认的调度器进程调度,但是如果在Pod 中提供了自定义的调度器名称,那么默认的调度器会忽略该Pod ,转由指定的调度器完成Pod的调度。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
schedulerName: my-scheduler
containers:
- name: nginx
image: nginx使用schedulerName: my-scheduler 指定调度器名称。如果指定的调度器在系统中还未部署,则默认调度器会忽略这个Pod,这个 Pod 将会永远处理Pending 状态。
可以用任何语言来实现简单或复杂的自定义的调度器,下面的例子使用Bash 脚本进行实现,调度策略为随机选择一个Node(注意,这个调度器需要通过kubectl proxy 来运行)
#!/bin/bash
SERVER='localhost:8001'
while true
do
for PODNAME in $(kubectl --server $SERVER get pods -o json | jq '.items[] | select (.spec.schedulerName == "my-scheduler") | select (.spec.nodeName == null) | .metadata.name' | tr -d '"')
do
NODES=($(kubectl --server $SERVER get nodes -o json | jq '.items[].metadata.name' | tr -d '"'))
NUMNODES=${ #NODES[@] }
CHOSEN=${ NODES [ $[ $RANDOM % $NUMNODES ] ] }
curl --header "Content-Type:application/json" --request POST --data '{"apiVersion":"v1","kind":"Binding","metadata":{"name":"'$PODNAME'"},"target':{"apiVersion":"v1","kind":"Node","name":"'$CHOSEN'"}}' http://$SERVER/api/v1/namespaces/default/pods/$PODNAME//binding/
echo "Assigned $PODNAME to $CHOSEN"
done
sleep 1
done一旦这个自定义调度器成功启动,前面的Pod应付被正确调度到某个Node上。