k8s安装报错集锦
2023/5/21...大约 6 分钟
故障1
[preflight] Some fatal errors occurred:
[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1
[ERROR FileContent--proc-sys-net-ipv4-ip_forward]: /proc/sys/net/ipv4/ip_forward contents are not set to 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
error execution phase preflight解决办法1
#配置内核参数,修改/etc/sysctl.conf,添加下面两条
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
#
添加完后,使用sysctl -p 使之生效故障2
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all Kubernetes containers running in docker:
- 'docker ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'docker logs CONTAINERID'
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster
To see the stack trace of this error execute with --v=5 or higher解决办法2
#查看systemctl status kubelet 状态是未启动
#查看日志 journalctl -xeu kubelet如下
Feb 15 10:35:04 localhost.localdomain kubelet[4690]: I0215 10:35:04.696691 4690 cni.go:240] "Unable to update cni config" err="no networks found in /etc/cni/net.d"
Feb 15 10:35:04 localhost.localdomain kubelet[4690]: I0215 10:35:04.701045 4690 docker_service.go:264] "Docker Info" dockerInfo=&{ID:677Q:3G4U:FNJ6:MHIX:QP35:5LD5:2ZJQ:EFCU:QU6F:LPQO:RJFQ:GN3P Containers:0 ContainersRunning:0 ContainersPaused:0 Co
Feb 15 10:35:04 localhost.localdomain kubelet[4690]: E0215 10:35:04.701062 4690 server.go:302] "Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"cgrou
Feb 15 10:35:04 localhost.localdomain systemd[1]: kubelet.service: main process exited, code=exited, status=1/FAILURE可以看到是 cgroup-driver问题
修改docker 默认cgroup-driver 为 systemd#在docker的配置文件,deamon.json 添加如下:
"exec-opts": ["native.cgroupdriver=systemd"]故障3
[init] Using Kubernetes version: v1.23.0
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-6443]: Port 6443 is in use
[ERROR Port-10259]: Port 10259 is in use
[ERROR Port-10257]: Port 10257 is in use
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher解决办法3
kubeadm reset故障4
[root@master ~]## kubectl get no
Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")
[root@master ~]## kubectl get pods
Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")解决办法4
rm -rf $HOME/.kube
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config故障5
coredns 处于pending 状态
coredns-6d8c4cb4d-h8wcs 0/1 Pending 0 112m
coredns-6d8c4cb4d-nfqpw 0/1 Pending 0 112m解决办法5
安装 flannel 网络,或其他网络
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml问题 6

flannel 一直处于 CrashLoopBackOff,查看 pods 的log
[root@master ~]## kubectl logs pods kube-flannel-ds-hbwqz -n kube-system
Error from server (NotFound): pods "pods" not found
[root@master ~]## kubectl logs kube-flannel-ds-hbwqz -n kube-system
I0216 05:37:43.173012 1 main.go:217] CLI flags config: {etcdEndpoints:http://127.0.0.1:4001,http://127.0.0.1:2379 etcdPrefix:/coreos.com/network etcdKeyfile: etcdCertfile: etcdCAFile: etcdUsername: etcdPassword: help:false version:false autoDetectIPv4:false autoDetectIPv6:false kubeSubnetMgr:true kubeApiUrl: kubeAnnotationPrefix:flannel.alpha.coreos.com kubeConfigFile: iface:[] ifaceRegex:[] ipMasq:true subnetFile:/run/flannel/subnet.env subnetDir: publicIP: publicIPv6: subnetLeaseRenewMargin:60 healthzIP:0.0.0.0 healthzPort:0 charonExecutablePath: charonViciUri: iptablesResyncSeconds:5 iptablesForwardRules:true netConfPath:/etc/kube-flannel/net-conf.json setNodeNetworkUnavailable:true}
W0216 05:37:43.173057 1 client_config.go:614] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
I0216 05:37:43.269060 1 kube.go:120] Waiting 10m0s for node controller to sync
I0216 05:37:43.269252 1 kube.go:378] Starting kube subnet manager
I0216 05:37:44.271223 1 kube.go:127] Node controller sync successful
I0216 05:37:44.271235 1 main.go:237] Created subnet manager: Kubernetes Subnet Manager - master
I0216 05:37:44.271237 1 main.go:240] Installing signal handlers
I0216 05:37:44.271314 1 main.go:459] Found network config - Backend type: vxlan
I0216 05:37:44.271321 1 main.go:651] Determining IP address of default interface
I0216 05:37:44.271449 1 main.go:698] Using interface with name enp0s3 and address 10.0.2.15
I0216 05:37:44.271483 1 main.go:720] Defaulting external address to interface address (10.0.2.15)
I0216 05:37:44.271486 1 main.go:733] Defaulting external v6 address to interface address (<nil>)
I0216 05:37:44.271517 1 vxlan.go:138] VXLAN config: VNI=1 Port=0 GBP=false Learning=false DirectRouting=false
E0216 05:37:44.271646 1 main.go:325] Error registering network: failed to acquire lease: node "master" pod cidr not assigned
W0216 05:37:44.271750 1 reflector.go:436] github.com/flannel-io/flannel/subnet/kube/kube.go:379: watch of *v1.Node ended with: an error on the server ("unable to decode an event from the watch stream: context canceled") has prevented the request from succeeding
I0216 05:37:44.271768 1 main.go:439] Stopping shutdownHandler...可以发现报错 Error registering network: failed to acquire lease: node "master" pod cidr not assigned
解决办法 6
需要保证 kube-controller-manager.yaml的地址和 kube-flannel.yml 文件是相同
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
--allocate-node-cidrs=true
--cluster-cidr=10.244.0.0/16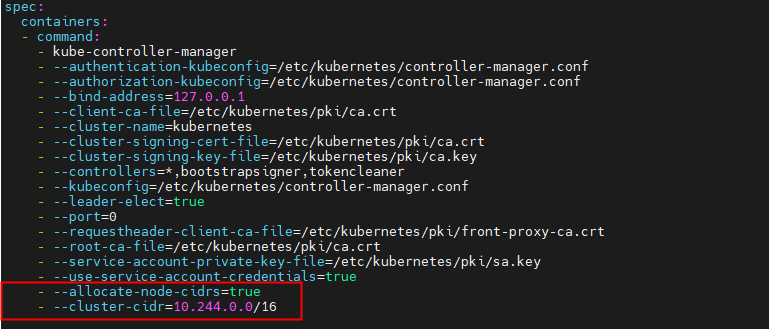
修复到相同后,重启kubelet ,systemctl restart kubelet
node 也需要修改
问题 7
node上的flannel 起不来,查看log 发现,无法访问 10.96.0.1:443
[root@master ~]## kubectl logs kube-flannel-ds-q2g2k -n kube-system
I0216 07:01:22.104311 1 main.go:217] CLI flags config: {etcdEndpoints:http://127.0.0.1:4001,http://127.0.0.1:2379 etcdPrefix:/coreos.com/network etcdKeyfile: etcdCertfile: etcdCAFile: etcdUsername: etcdPassword: help:false version:false autoDetectIPv4:false autoDetectIPv6:false kubeSubnetMgr:true kubeApiUrl: kubeAnnotationPrefix:flannel.alpha.coreos.com kubeConfigFile: iface:[] ifaceRegex:[] ipMasq:true subnetFile:/run/flannel/subnet.env subnetDir: publicIP: publicIPv6: subnetLeaseRenewMargin:60 healthzIP:0.0.0.0 healthzPort:0 charonExecutablePath: charonViciUri: iptablesResyncSeconds:5 iptablesForwardRules:true netConfPath:/etc/kube-flannel/net-conf.json setNodeNetworkUnavailable:true}
W0216 07:01:22.104349 1 client_config.go:614] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
E0216 07:01:52.105453 1 main.go:234] Failed to create SubnetManager: error retrieving pod spec for 'kube-system/kube-flannel-ds-q2g2k': Get "https://10.96.0.1:443/api/v1/namespaces/kube-system/pods/kube-flannel-ds-q2g2k": dial tcp 10.96.0.1:443: i/o timeout解决办法 7
在master 上查看
kubectl get svc
#可以看到 10.96.0.1:443在master curl 测试也是可以通的。
原因是我配置了双网卡,默认路由走的上可以上网的那个网卡,所以无法访问
在node 上添加路由,路由为 --service-cluster-ip-range=10.96.0.0/12 即可
#vim /etc/sysconfig/network-script/route-enp0s8 ,我的k8s 使用的网卡是 enp0s8
10.96.0.0/12 dev enp0s8问题 8
多网卡环境flannel 配置导致网络不可用解决办法 8
主机模式下有多个网卡,eth0 网卡用于 nat 转发访问公网,而 eth1 网卡才是主机真正的 IP,在这种情况下直接部署 k8s flannel 插件会导致 CoreDNS 无法工作.
如果Node有多个网卡的话,参考flannel issues 39701,目前需要在kube-flannel.yml中使用--iface参数指定集群主机内网网卡的名称,否则可能会出现dns无法解析。需要将kube-flannel.yml下载到本地,flanneld启动参数加上--iface=<iface-name>